

核心時脈方面,GeForce RTX 3060 Ti 預設時脈為 1410 MHz Base Clock 及 1665 MHz Boost Clock,最高 TDP 為 200W。但記憶體還是沿用 GDDR6 記憶體顆粒,8GB 記憶體容量,1750 Mhz 時脈及傳輸速度 14 Gbps,具備 256 bit 記憶體頻寬介面,總頻寬為 448GB/s。
經改良的 Ampere SM 架構
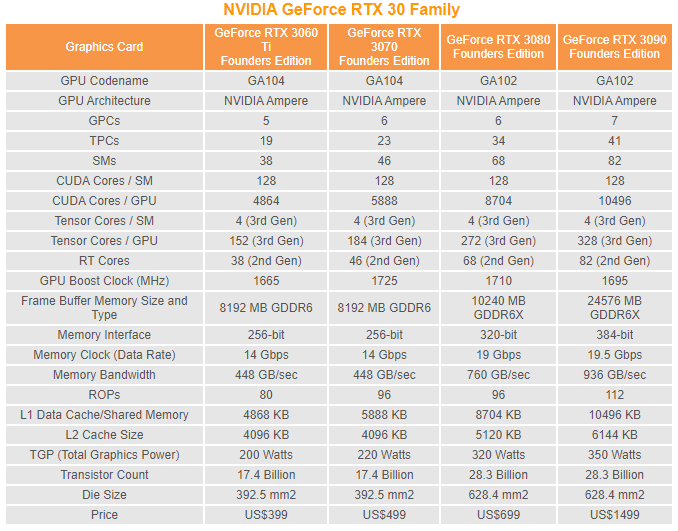
「GA104」核心採用全新的「Ampere」GPU 微架構,主要改良在 SM 串流多處理器的設計,上代 Turing SM 首次在 SM 模組內增設 INT32 運算單元,每個 SM 模組內共有 64 個 FP32 CUDA、64 個 INT32 運算單元,每個 SM 分區均擁有 1 條 FP 與 1 條 INT 數據路徑,因此每個 Turing SM 在每在週期都可以處理 64 個 FP32 及 64 個 INT32 的操作。
不過在現代的遊戲負載有更廣泛的運算需求,許多工作負載都混合使用 FP32 運算指令 (如 FFMA、FADD 及 FMUL),同時亦具備簡單的INT 整數指令(如尋址、加法、浮點比較,大小值等),指令平均比例 FP : INT 約為 100:36,因此 Ampere GPU 針對 FP32 與 INT32 運算加入更具效率的調度。
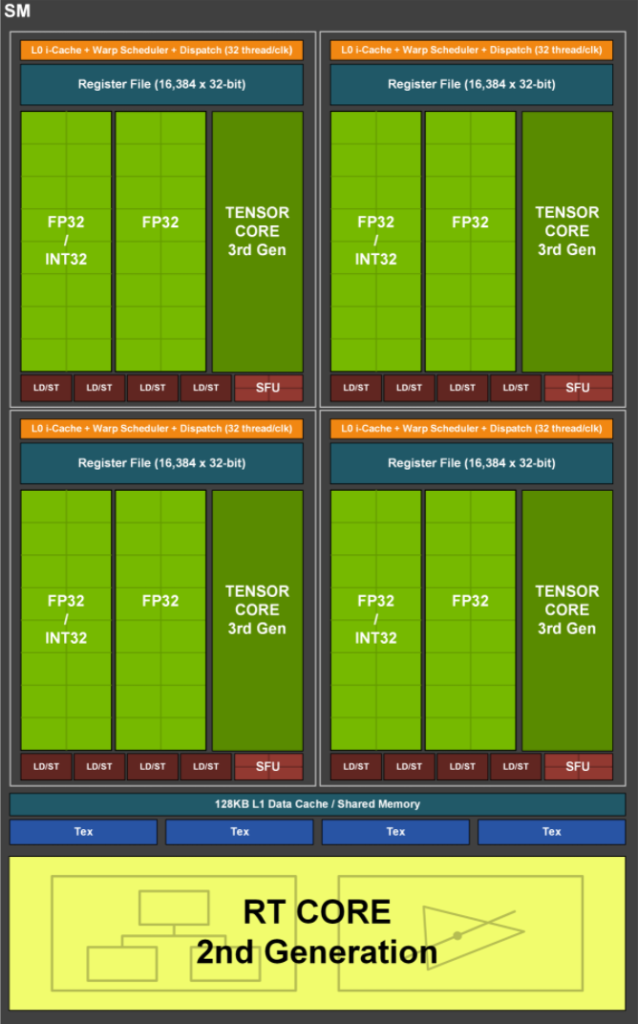
所以新的 Ampere SM 設計將 SM 模組改為 128 個 FP32 CUDA 運算單元,當中一半兼備 INT32 運算能力,同時將每個 SM 分區的 2 組數據路徑均可用於 FP 運算,但其中 1 組可調用於 INT 運算,這樣使每一個週期可處理 128 個 FP32,或調整至 64 FP32 + 64 個 INT32 運算。升級後的 Ampere SM 模組可將 FP32 運算能力提升 1 倍,而又可以應對不同的運算需求,使核心更有彈性和更有效率,尤其在啟用 Ray Tracing 後,更多的FP32 運算操作得以應付,因此 Ampere GPU 在 Ray-Tracing 的性能表現提升上會更為明顯。此外,Ampere SM 繼續支援由 Turning GPU 微架構開始加入的雙速 FP16 (HFMA) 運算操作,一般的 FP16 運算會交由 Tensor Cores 處理。
更大 L1 Data Cache 設計
Ampere SM 核心沿用了 L1 Cache、Texture Cache 及 Share Memory 整合的統一共享緩存設計,每個 SM 的 L1 Cache 容量由 96KB 提升至 128KB,較上代提升了 33%,同時提供更具彈性的分割,支援 6 種不同分割配置:
• 128 KB L1 + 0 KB Share Memory
• 120 KB L1 + 8 KB Share Memory
• 112 KB L1 + 16 KB Share Memory
• 96 KB L1 + 32 KB Share Memory
• 64 KB L1 + 64 KB Share Memory
• 28 KB L1 + 100 KB Share Memory
當圖形工作或混合運算模式下,Ampere SM 則會將 L1 Cache 分配為 64 KB Texture Cache (較上代提升1倍)、48KB Share Memory 及 16KB L1 Cache 保留於 Graphics Pipeline 運算用途。除了 L1 Cache 容量增加外,L1 Cache 的頻寬比上代也提升了一倍,由於上代每個週期 64 bytes/clock 提升至 128 bytes/clock,此可簡代了編程所需要的調度優化需求,頻寬提升達一倍,延遲大幅降低。


{kind=link}