

GeForce RTX系列登場
NVIDIA 19 日正式發佈全新「Turing」GPU 微架構繪圖卡產品,包括核心代號為「TU102」的旗艦級「GeForce RTX 2080 Ti」,以及核心代號「TU104」的效能級「GeForce RTX 2080」,它是十多年來 GPU 最大的架構躍進,包括新增 Tensor 核心、RT 核心及許多新的進階著色功能,透過全新硬體加速引擎及混合渲染技術,能實時提供光線追踪渲染,提供更逼真的物體陰影、反射及折射效果,除了性能表現進一步提升外,更將 PC 遊戲真實感帶進另一個層次。

與 NVIDIA「Turing」GPU 微架構開發並行,Microsoft 在 2018 年初宣佈全新 A.I 人工智能及 DXR 光線追踪的 DirectML API,令遊戲開發人員可以快速部署 A.I 人工智能技術與光線追踪於新遊戲中,融合光柵化、實時光線追踪、人工智能和模擬,在 PC 遊戲中實現令人難以置信的真實感,神奇網絡提供驚人的新效果、電影級交互式體驗和流暢創建或導航複雜 3D 模型的交互性。

此外,全新「Turing」GPU 還承繼了「Volta」微架構中所有增強的「CUDA」功能,例如獨立線程調度、針對多個 CUDA 應用的地址空間隔離 MPS 硬體加速能力以及全新的協作加速,令新一代 GeForce RTX 繪圖卡的「CUDA」運算能力更靈活、性能更強大。
12nm FFN 制程、TU104 繪圖核心
NVIDIA 「Turing」 GPU 架構相較上代「Pascal」更為複雜,上代「GP104」繪圖核心採用 16nm 制程、內建 73 億個電晶體,Die Size 為 314mm² 、 TDP 為 180W;全新「TU104」繪圖核心增至 136 億個電晶體,受惠於全新TSMC 12nm FFN 制程配合 VLSI 超大型積體電路優化,雖然 Die Size 增至 545mm²,運算單元數目大幅提升,但 TDP 僅輕微上升至 215~225W 水平,但性能功耗表現更上一層樓。
NVIDIA「TU104」繪圖核心是基於「TU102」按比例作縮減,完整的「TU104」晶片內包括了 6 個 GPC 圖形處理群,24 個 TPC 紋理處理群集及 48 個 SM 串流多處理器。

每個 GPC 內擁有一組獨立的 Raster Engine 光柵處理引擎及 4 個 TPC 紋理處理群集,每個 TPC 群集包含 2 個 SM 模組,每個 SM 內建 64 個 CUDA Cores、8 個 Tensor Cores、1 個 RT Cores、256KB Register File 及 4 個 Texture Units,並擁有 96KB L1 Cache/Shared Memory 可因應運算或圖形工作負載作出可改變的配置。
每個 SM 單元具備兩個 FP64 運算單元,總數合共 96 個 FP64 運算單元,但圖中並沒有標示出來,它的作用是確保 FP64 代碼的程式可以正常運作,但並非主要的硬體運算單元。
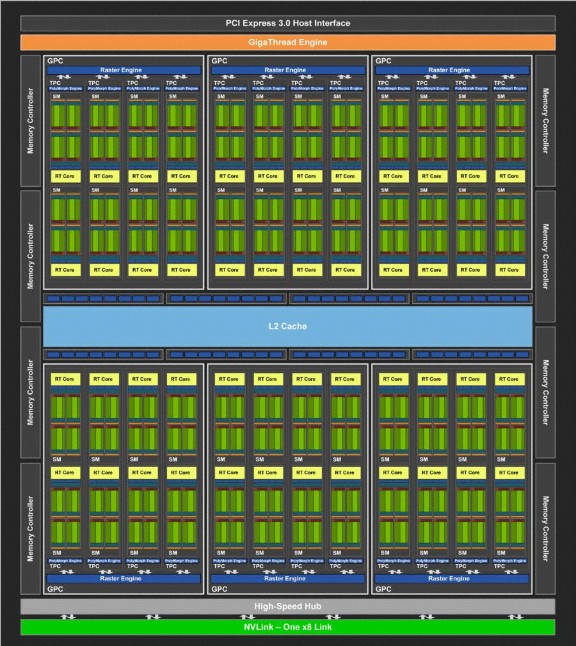
內建 8 個 32 bit GDDR6 記憶體控制器、總共 256bit 記憶體頻寬,每個記憶體控制器綁定 8 個 ROP 單元及 512KB L2 Cache,完整的「TU104」晶片合共擁有 64 個 ROP 單元及 4,096KB L2 Cache。
值得注意的是,暫時僅「Quadeo RTX 6000」繪圖卡擁有完整「TU104」繪圖核心規格,針對 3D 遊戲市場的「GeForce RTX 2080 」所採用的是「TU104-400A」繪圖核心,部份運算單元、記憶體控制器將被屏蔽。
全新的 Turing SM 架構
NVIDIA「TU104」繪圖核心採用全新「Turing」GPU 微架構,當中包括了「Volta」GPU 微架構中引入的多項新功能,每個 TPC 擁有 2 組 SM 模組,每個 SM 模組內共有 64 個 FP32、64 個 INT32 運算單元,具備 FP32 與 INT32 運算並行能力,與「Volta」GPU 微架構的獨立線程調度設計非常類似,同時還內建了 8 個混合精度的 Tensor Cores 及 1 個專門作光線追蹤運算的 RT Core。

全新的「Turing」SM 模組內部劃分為 4 個區塊,每個區塊擁有 16 個 FP32 運算單元、16 個 INT32 運算單元、2 個 Tensor 核心,1 個 Warp 調度器及 1 個 Dispatch 調度單元,每個區塊擁有 1 個全新的 L0 Instruction Cache 及64KB Register File 暫存器,整個 SM 則共享 1 組 96KB L1 Data Cache 或用作 Shared Memory。
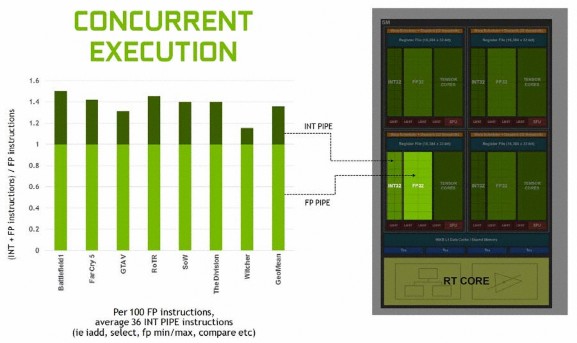
「Turing」SM 模組其中一個重大改良是核心的數據執行路徑,現時的著色器工作負載通常混合使用 FP 運算指令 (FADD/FMAD) 及簡單的 INT 運算指令,INT 指令常見用於尋址和獲取數據的整數加法、浮點比較、用於處理結果的最小/最大值等等,以往「Pascal」SM 模組只要處理非 FP 運算,整個浮點執行數據路徑就會處於閒置狀態,「Turing」SM 模組就特別新增多一組 INT 數據執行路徑,令 FP 運算與 INT 運算可以並行處理,令整體指令吞吐量性能提升約 36%。
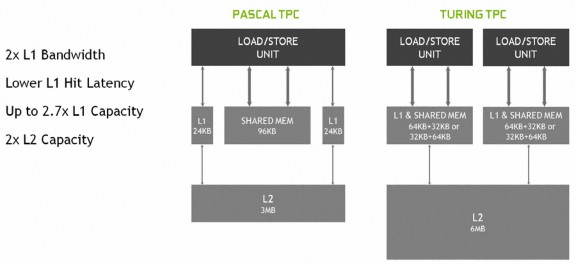
此外,「Turing」SM 架構改用 L1 Cache、Texture Cache 及 Share Memory 整合的全新統一共享緩存設計,同時容許 Share Memory 容量重新配置以擴大規模,令 L1 Cache 大小可提升至最高 64KB,新設計可將 L1 Cache 與Share Memory 性能進一步提高,同時簡化了編程所需的調度優化需求,相較上代「Pascal」 的 L1 Cache 頻寬提升達 1 倍並大幅降低了延遲。
整體而言,「Turing」SM 架構透過大幅的改良 CUDA Cores 部份,相較上代「Pascal」的 CUDA Cores 在性能方面能夠提升達 50% 甚至更高。
新增 Tensor Core 運算單元
全新「Turing」GPU 微架構加入增強型的 Tensor Core 運算單元,這是專門用於執行向量及矩陣運算的運算單元,包括 INT8 及 INT4 精度的函數運算,以及更高精度的 FP16 運算工作,主要用於深度學習神經網絡運算、推理運算、矩陣運算等,提供更佳的硬體加速能力。

針對遊戲應用層面,Tensor Cores 其中一個重點就是加入全新 DLSS 深度學習超級採樣技術,透過深度神經網絡提取渲染場景的多維特徵,並智能地組合來自多個幀的細節,以構建高質量 3D 影像。與傳統的 AA 技術相比,DLSS 使用更少的輸入樣本,同時避免了透明度和其他復雜場景元素的算法難度。
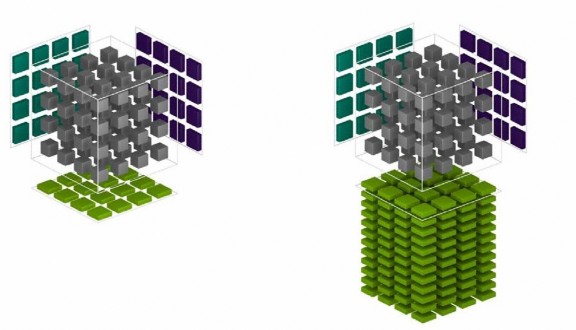
Pascal向量核心與Turing Tensor Core數目比較
全新「Turing」SM 模組內建 8 個 Tensor Cores,每個 Tensor Core 單一週期可執行 64 個 FMA 浮點融合乘加運算、64 個 FP16 乘法累加運算、128 個 FP16 運算、256 個 INT8 精度運算或 512 個 INT4 精度運算。
全新 RT Core 運算單元
Ray Tracing 光線追踪技術是一種密集型渲染技術,可以逼真地模擬場景及物件的光線,實時以物理方式渲染正確的反射、折射、陰影及間接照明效果。過去的 GPU 架構並無法對遊戲及圖形進行複雜的實時光線追踪處理,NVIDIA 經過過 10 年的研究及開發,終於在新一代「Turing」GPU 微架構中加入硬體光線追踪加速引擎 —「RT Cores」,結合 NVIDIA RTX 軟件引擎,實現逼真的實時光線場景效果。
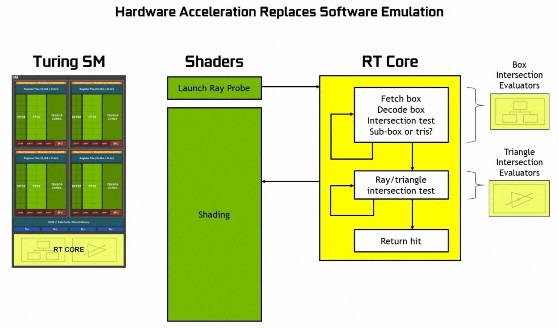
全新「Turing」SM 模組內均擁有 1 個 RT Core,提供 BVH 邊界體積層次遍歷及射線三角測試硬體加速運算,從而節省了 SM 模組對每條光線的額外處理。每個 RT Core 內含兩個專用單元,第一個單元進行邊界框架測試,第二個單元進行射線三角交叉測試。
「Turing」SM 模組只需啟動射線探測器,RT 核心執行 BVH 遍歷和射線三角測試,並向 SM 返回命中或不命中,SM 可以空置並執行其他圖形或運算工作。

受惠於全新 RT Cores 運算單元,全新「Turing」繪圖核心的光線跟踪性能,相較上代「Pascal」繪圖核心有明顯增長,使用「GeForce GTX 1080」繪圖核心執行軟體光線射踪每秒可達成 0.89 Giga Rays,但使用「GeForce RTX 2080」繪圖核心則可達至 8 Giga Rays,支援NVIDIA RTX、Microsoft DXR 及 Vulkan API,為遊戲和專業應用提供令人難以置信的逼真和物理精確的圖形。
全新 GDDR6 記憶體控制器
記憶體子系統對性能表現絕對是至關重要,全新「Turing」GPU 微架構特別針對記憶體控制器、高速緩存設計及壓縮技術作出改良,以增加記憶體頻寬及減少讀取延遲,其中一大改進是全新 GDDR6 記憶體控制器,配合更高的 GDDR6 記憶體顆粒,以滿足功能更強大的著色器與更加複雜的渲染技術。
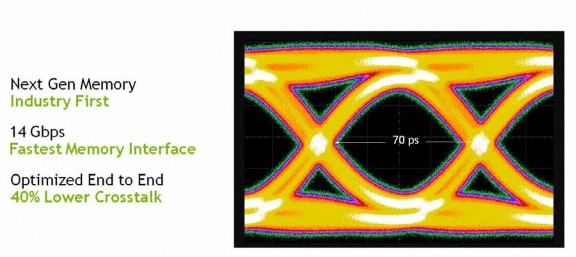
GDDR6 是新一代高頻寬 GDDR DRAM 記憶體顆粒,透過全新的 SerDes 及 RF 增強技術,實現更高的時脈及傳送速度,NVIDIA 特別針對記憶體控制器作出改良,透過訊號及電源完整性,針對 GPU 封裝及電路板設計作出優化,其中最明顯的改善是將 Crosstalk 訊號干擾減少 40%,大幅減少因制程、溫度、電源電壓所引起的訊噪及變化,相較上代「Pascal」傳送速度由11Gbps 提升至 14Gbps,性能提升達 20%。

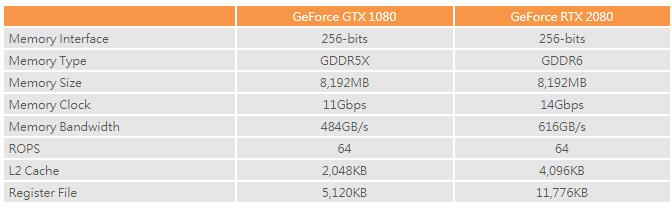
全新「GeForce RTX 2080」內建 8 個 GDDR6 記憶體控制器、合共 256bit 記憶體頻寬介面,配搭 14Gbps GDDR6 記憶體顆粒,提供高 達448GB/s 記憶體總頻寬。
更大、更快的 L2 Cache
除了全新的 GDDR6 記憶體控制器外,「Turing」GPU 同時改良了 L2 Cache 緩存設計,上代「GeForce GTX 1080」繪圖核心提供 2MB L2 Cache 容量,全新「GeForce RTX 2080」繪圖核心提升至 4MB L2 Cache,同時 L2 Cache 頻寬速度亦相較上代提升達 1 倍。
ROP 設計方面,「Turing」GPU 設計與上代「Pascal」大致相同,每個 ROP 模組內包含 8 個 ROP 運單元,每個 ROP 單元單一週期可處理一個單色樣本,「GeForce RTX 2080」繪圖核心共有 8 個 ROP 模組、合共 64 個 ROP 運算單元。
Turing 記憶體壓縮引擎
除了改用更高速的 GDDR6 記憶體顆粒外,全新「Turing」GPU 微架構繼續針對 Delta Color 色彩壓縮技術入手,利用無損儲存壓縮方式來降低對記憶體及 L2 Cache 頻寬的需求量,今代的壓縮模式變得更具靈活性及彈性,同時提供了更高的壓縮比,以提升資料的壓縮比進一步節省頻寬所需。

總括而言,全新「GeForce GTX 2080」受惠於全新的 GDDR6 記憶體顆粒,記憶體時脈提升至 14Gbps,相較上代「GeForce GTX 1080」記憶體頻寬提升約 25%,再加上經改良的 Turing 記憶體壓縮技術,記憶體有效頻寬相較上代大幅提升了 50%+。
升級 DisplayPort 1.4a、支援 8K @ 60Hz
為迎接 8K 輸出時代,全新「TU104」繪圖核心更新了顯示輸出引擎,由上代「GeForce GTX 1080」支援 DisplayPort 1.3 版本,原生最高支援 5K @ 60Hz解析度,如需要援 8K @ 60Hz 需要使用兩組 DisplayPort 線纜。全新「GeForce RTX 2080」升級至支援 Display Port 1.4a 版本,只需單一 Display Port 線纜即可提供 8K @ 60Hz 解析度,更支援 VEGA DSC 1.2 技術提供更高壓縮的無損顯示功能。
| Bandwidth/Link | Max Resolution | |
| DisplayPort 1.2 | 5.4Gbps | 4K@60Hz |
| Displayport 1.3 | 8.1Gbps | 5K@60Hz |
| DisplayPort 1.4a | 8.1Gbps | 8K@60Hz |
此外,全新「TU104」顯示輸出引擎管道加入了原生 HDR 處理功能,將 HDR 色調映射功能增添至顯示引擎管道中,這是近似標準動態範圍顯示器上使用的高動態圖像外觀處理,並符合 ITU-R BT.2100 色調映射標準,能避免不同 HDR 顯示器上的色彩偏移。
新增 H.265 8K 編碼支援
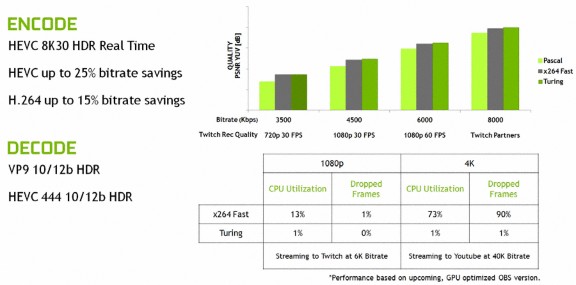
全新「TU104」繪圖核心升級提供增強型的 NVENC 編碼器單元,除了新增支援 H.265 (HEVC) 8K 編碼外,編碼表現亦相較上代「GP104」有明顯改善,在相同編碼質量下 HEVC 相較上代可節省約 25% 比特率、H.264 則可節省約 15% 比特率。
此外,「TU104」繪圖核心亦更新了 NVDEC 解碼器單元,支援更多視頻解碼格式,新增 H.265 8K @ 30Hz、VP9 10/12b HDR及 HEVC YUV 4:4:4 8/10/12b HDR 解碼功能。
全新 VirtualLink 接口
為推動 VR 眼鏡的普及,全新「GeForce RTX 2080」繪圖卡新增「VirtualLink」接口,它是由 AMD、MICROSOFT、NVIDIA、OCULUS 及 VALUE 推動的全新開放式業界標準,只需單一線纜就能取代舊有供電、HDMI 及 USB 連接,提升 VR 眼鏡的方便性。
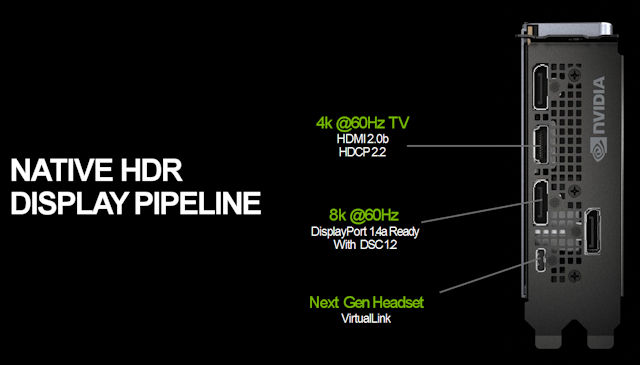
「VirtualLink」是基於 USB Tyep-C 接口規格,但卻具備 4 個 HBR3 DisplayPort 顯示通道,並同時擁有 2 個 SuperSpeed USB 3 連接通道。相比一般 USB-C 接口最高只能提供 4 個 HBR3 DisplayPort 顯示通道,或是 2 個 HBR3 DisplayPort + 2個SuperSpeed USB 3,提供更大的顯示擴展性。
此外,「VirtualLink」標準接口可提供最高 35W 電源輸出,令新一代的 VR 眼鏡只需單一 USB-C 線纜,就能取代過往的 HDMI、供電及 USB 連接線材,緩解舊有 VR 眼鏡設線材設置麻煩的問題。
第二代 NVLink 技術

在「Pascal」GPU 微架構之前,NVIDIA 繪圖卡要達成多卡協同運算時,會透過卡頂的 SLI MIO 接橋將最終渲染結果傳送至主GPU,但舊有 SLI MIO 接橋速度只有約 1GB/s,根本無法滿足現今遊戲對 GPU to GPU 的數據傳輸需求,因此 NVIDIA 於「Pascal」GPU 微架構中加入了 SLI HB 技術,它其實是雙路的 SLI MIO 接口,但頻寬亦只有 2GB/s 無法滿足更高解析度及更新率需求。
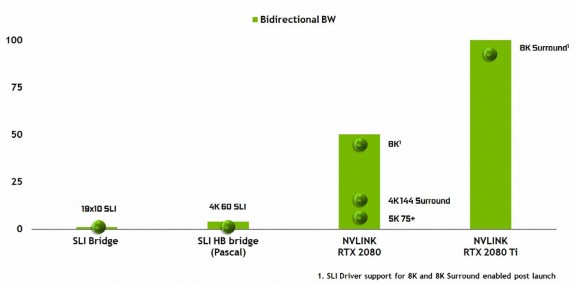
新一代「Turing」GPU 微架構升級至第二代 NVLink 技術取代老舊的 SLI 接橋,全新「GeForce RTX 2080」具備 1 組第二代NVLink x8 接鏈,每組可提供約 25GB/s、合共 50GB/s 雙向頻寬,實現以往無法達成的高級顯示拓樸結構,滿足高達 8k Surround 顯示需求。
值得注意的是,NVLink 僅支援 2-Way SLI 技術,因此不會再提供 3-Way 或 4-Ways SLI 配置,第二代 NVLink 接穚定價為 US$ 79,備有 Dual Slot、Triple Slot 版本可供選擇。
Source : https://www.hkepc.com/17211