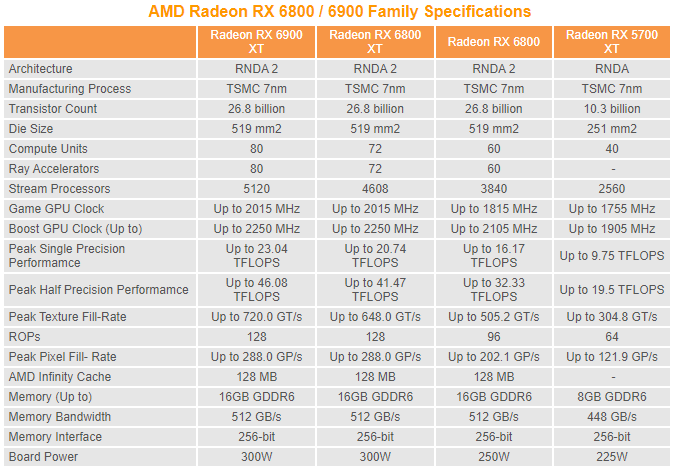
前端換上了重新設計的 RB+ 光柵化單元,每個 Shader 引擎共享 32 個 RB+ 單元,數目跟上一代 RDNA 相同,但每個週期能處理 8 個 32bit Pixel 指令,數目是上一代的 1 倍,更重要是新增 Variable Rate Shading (VRS) 可變速率著色、Mesh Shaders 網格著色器、Sampler Feedback 取樣器回饋等功能,以滿足 DirectX 12 Ultimate 規格的要求,允許遊戲選擇性地降低畫面裡部分區域的細節水平來提高效能,對圖像品質幾乎沒有明顯影響,性能卻進一步提升。
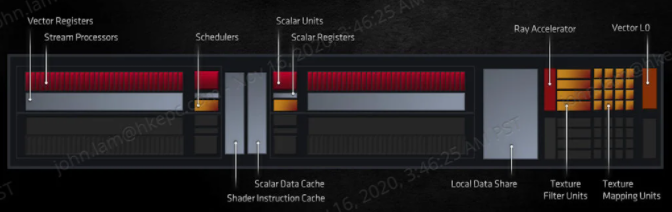
RDNA 2 微架構與 RDNA 同樣採用 Dual Compute Unit (DCU) 設計,將 2 個 CU 結合在一起,共用 Scalar Data Cache、Shader Instruction Cache 及 Local Data Share,DCU 設計可以讓 Shader Processor 之間有更佳的並行運算能力,今代積累 Zen CPU 研發時所得出的高時脈設計經驗,RDNA 2 加入了 Streamlined Micro-Architecture 設計,DCU 的 Pipeline Logic 佈局修改後,令運作時脈可以在相同功下提升 1.3X。

RDNA 2 微架構在每一個 CU 中加入了 Ray Accelerator (RA) 硬體加速運算單元,屬於軟硬體混合加速方式,實現支援光線追踪影像特效,它是基於 Microsoft Raytraing (DXR) API 而設計,每個 Ray Accelerator 在每個時脈可以完成 4 Ray/Box 或 1 Ray/Triangle 的光線相交運算,運算速度較純軟件運算提昇約 10 倍,雖然與 NVIDIA 的 RT 硬體運算單元設計還有一點距離,但至少 Ray Tracing 已不再是 NVIDIA 的專利。
AMD 全新的 Inifinity Cache 技術

有別於 NVIDIA 採用更高頻寬的 GDDR6X 記憶體,AMD 的做法明顯比 NVIDIA 聰明,在 RDNA 2 微架構中,首次加入 Infinity Cache 技術,在 L2 Cache 與 GDDR6 之間加入了 128 MB 緩存,GPU 與 Infinity Cache 之間由 16 條 64bit 1.94 Ghz 的 Infinity Fabric 連結,頻寬基本上是 256bit GDDR6 記憶體的 4 倍。
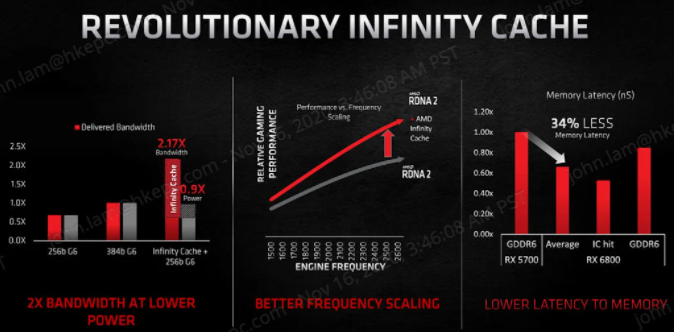
據 AMD 指出,Infinity Cache 將能大幅提升遊戲 Workload 資料的命中率,降低讀取延遲達 34%,並減少 GDDR6 記憶體的頻寬使用,實際性能表現近乎 384bit GDDR6 的 2.17 倍,但卻只需要 384bit GDDR6 的 0.9X 功脈,Infinity Cache 可以說是 RDNA 2 微架構最重要的昇級。
搭配 Ryzen 5000 支援 Smart Access 技術
除了 Infinity Cache 技術外,RDNA 2 微架構另一項重要的記憶體改良就是 Smart Access Memory 技術,傳統的 x86 PC 架構中受限於 PCIe 規範,只能透過 Base Address Register (BAR) 每次將 256MB 系統記憶體射映到 GPU 記憶體,這個限制嚴重影響到系統記憶體與 GPU 記憶體之間的資料傳輸效率。

AMD 在 RDNA 2 中加入了 Smart Access Memory 技術,當用家使用 AMD 新一代 Ryzen 5000 系列處理器時,不再使用 PCIe Mapping 的方式,CPU 可以直接存取 GPU 的記憶體,完全解除 CPU 與 GPU 之間的讀寫瓶頸,遊戲性能平均能提升約 6%,尤其對大量使用 Texture 貼圖的遊戲,效能提升會更為明顯。