
加強 Execution Engine 的平行處理能力
有別於 Intel Core 微架構採用的 Unified Reservation Station 設計,AMD Zen 3 微架構選擇分割出獨立的 INT 整數及 FP 浮點運算群,令各自擁有專屬的流水線及執行端口,雖然這樣會令電晶體和晶片面積增加,但卻擁有更佳的並行運算能力,這就是 AMD 為何在 SMT 同步多線程運算性能比 Intel 的 Hyper-Threading 出眾。
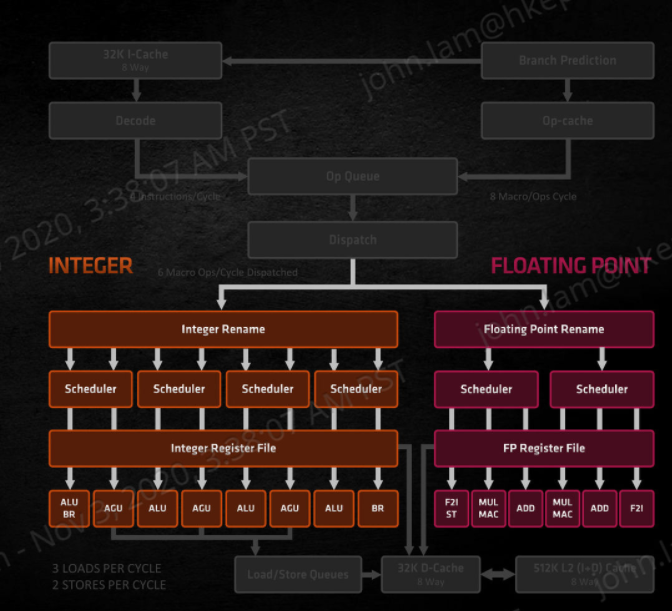
AMD Zen 3 微架構中,特別針對 Execution Engine 設計作出了改良,擁有更寬的 Floating Point 及 Integer Issue 單元、更高性能的 FMAC 單元、更大的 Execution Window 及全新的 Integer Data Picker 單元,目的是進一步降低運算延遲,並進一步提高指令層面的平行運算能力。相較 Zen 2 的每個週期 7 個 Issues 提升至 10 個。
AMD Zen 3 微架構的 INT 整數運算群保持每個週期可處理 6 個整數 μOps 指令,內部針對 Instruction Scheduler 調度單作也作出了改良,擁有 4 個 24-Entry ALU/AGU Scheduler 單元,能同時處理 Schedule Queue 總數由上代 92 個增至 96 個,擁有 4 個 ALU 單元、3 個 AGU 單元、1 個獨立 Branch 單元及 2 個 St-Data 單元,整數運算流水線由上代 7 條增加至 10 條,所以運算能力大幅提升。
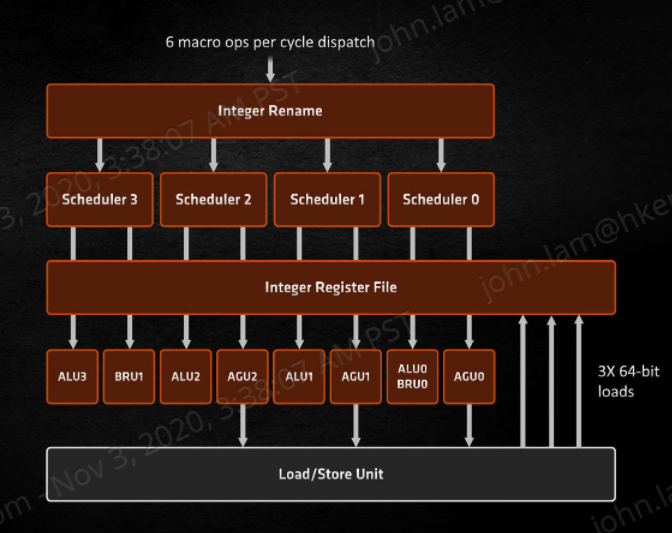
為減少單元閒置造成的資源浪費,AMD Zen 3 微架構將整數 Register 暫存器數目由 180 個增加到 192 個,能提升亂序執行能力,同時避免 μOps 指令不必要地順序執行,從而提升處理器指令層級的運算性能。此外,擴大了 Reorder Buffer 單元,將隊列暫存數目由 224 個增加至 256 個,改為 4 個可共享的 Schedule Queue 單元,提供更靈活的調度,增強指令排序能力降低單元閒置,改善 SMT 同步多線程運算表現。
Floating Point 浮點性能提升
在浮點運算方面,AMD Zen 3 微架構的 FP 浮點運算群設計有明顯的改良,μOps Dispatch 寬度由 4-Wide 增至 6-Wide,每個週期可處理 6 個浮點 μOps 指令,設有 2 組 Instruction Scheduler 週度單元,能同時處理的 Schedule Queue 總數由上代 100 個增加至 128 個。
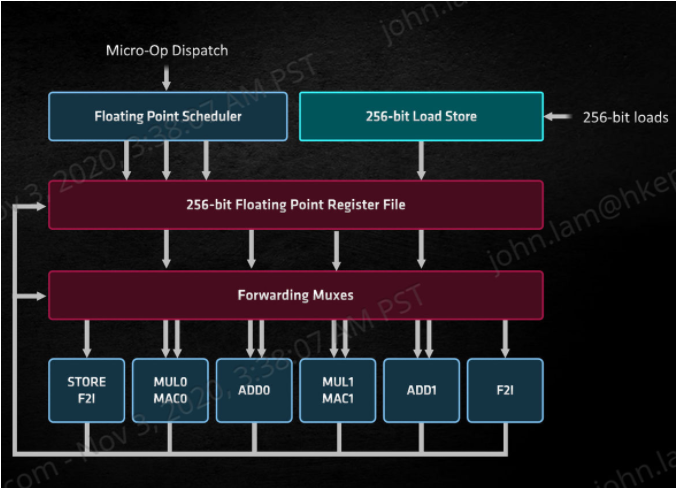
核心內有一個 256 bit Load Store 單元,能在 Backup Queue 中提取 μOps 指令,能省略再經 Scheduler Queue 提前分派調度,浮點 Register 暫存器數目則保持 160 個,可直接與整數暫存單進行資料交換,增加浮點亂序執行能力。AMD Zen 3 除了 2 個 ADD 加法端口及 2 個 MUL 乘法端口外,另外設有獨立的 F2I 及 FSI/STORE 單元,相較上代 Zen 2 最大分在於 FMAC 加乘運算性能,Zen 3 延遲值由上一代的 5 Cycles 減至 4 個 Cycles,面對 AVX/AVX2 指令、AES 運算引擎用作加密/ 解密運算能力明顯提升。